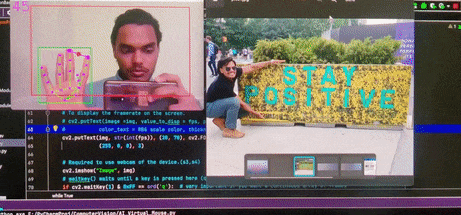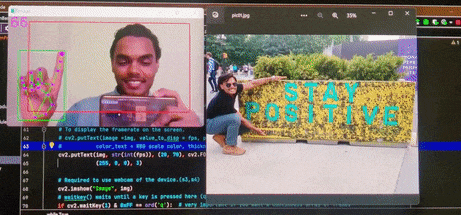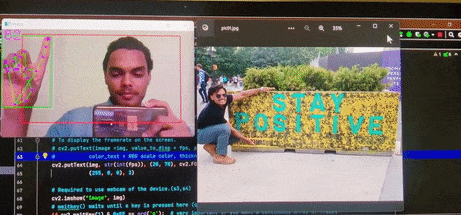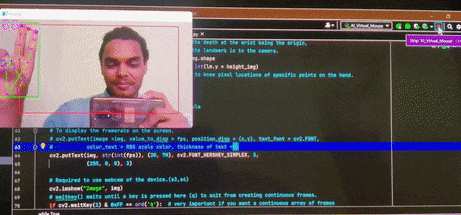
Brief : A gesture control mechanism which makes use of a camera to capture the finger movements of a hand and alter the sound of the host system. This version
is designed for desktop use.
Code Read Me
Virtual Mouse Control
Brief : A gesture control mechanism which makes use of a camera to capture the finger movements of a hand and move the mouse pointer on the desktop.
Further, this model also supports single and double clicks with certain finger movements. This version is designed for desktop use.
Code Read Me
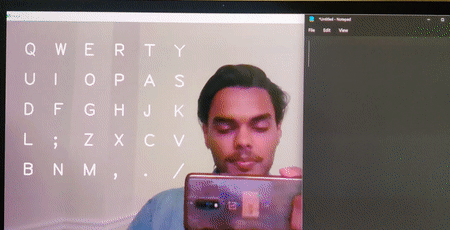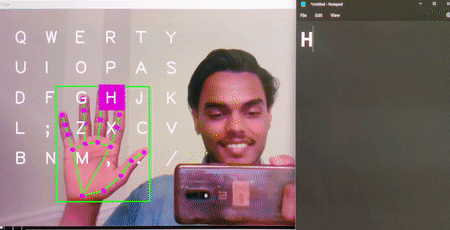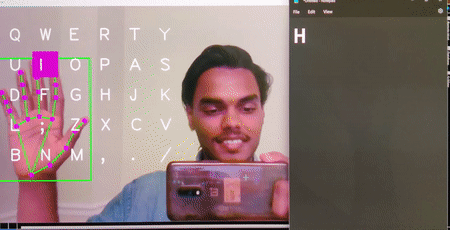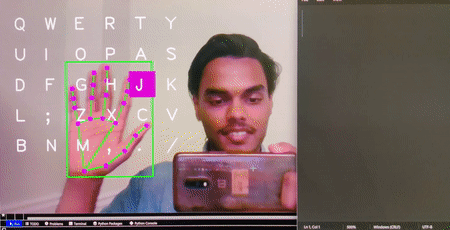
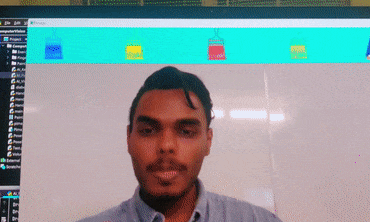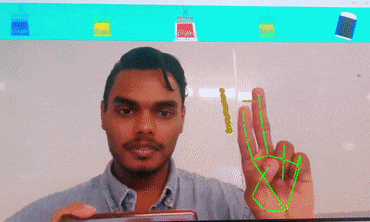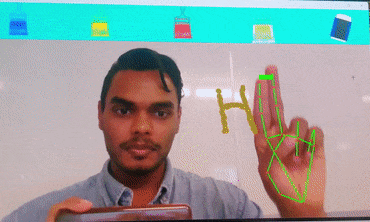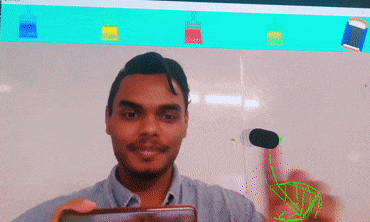
Virtual Keyboard
Brief : A gesture control mechanism which makes use of a camera to capture the finger movements of a hand and type the letters as selected on the desktop screen.
This version is designed for desktop use and is able to write text on popular apps such as notepad++, Word, etc.
Code Read Me
Virtual Painter
Brief : A gesture control mechanism which makes use of a camera to capture the finger movements of a hand and paint on the desktop screen
within the reference box. Currently it supports four different colors and the eraser option.
This version is designed for desktop use.
Code Read Me
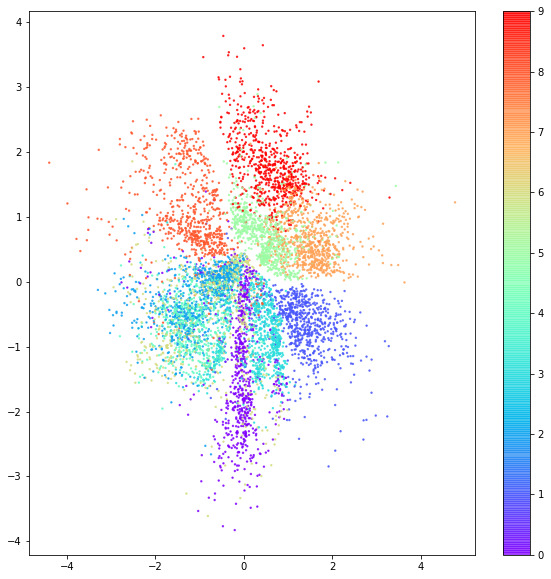
Img Title: Latent Space Distribution of the Variational AutoEncoder (VAE)
Brief : A Variational Autoencoder (VAE) is a machine learning model that learns to generate new data by understanding the underlying patterns in the training dataset. It uses
probabilistic techniques to capture the distribution of the data and produces diverse outputs. I have developed this VAE using TensorFlow and the Keras
functional API to perform dataset generation. The VAE model has been trained on the fashion MNIST dataset.
The depicted figure above illustrates the distribution of the latent space in the model, while the subsequent figure below showcases the output generated by my VAE.
Code Read Me
Variational AutoEncoder for Sound Generation
Original Sound
Generated Sound
Brief : A Variational Autoencoder (VAE) is a machine learning model that learns to generate new data by understanding the underlying patterns in the training dataset.
It uses probabilistic techniques to capture the distribution of the data and produces diverse outputs. I have implemented a Variational Autoencoder (VAE) using TensorFlow
and the Keras functional API for the purpose of sound generation. This VAE model has been trained on the
free spoken digits dataset. The audio representation embedded above depicts the original audio utilized during the training process, as well as the audio generated
by the model, which is generated based on sampled mel spectrograms.
Code Read Me
Generative Adversarial Network for Image Generation
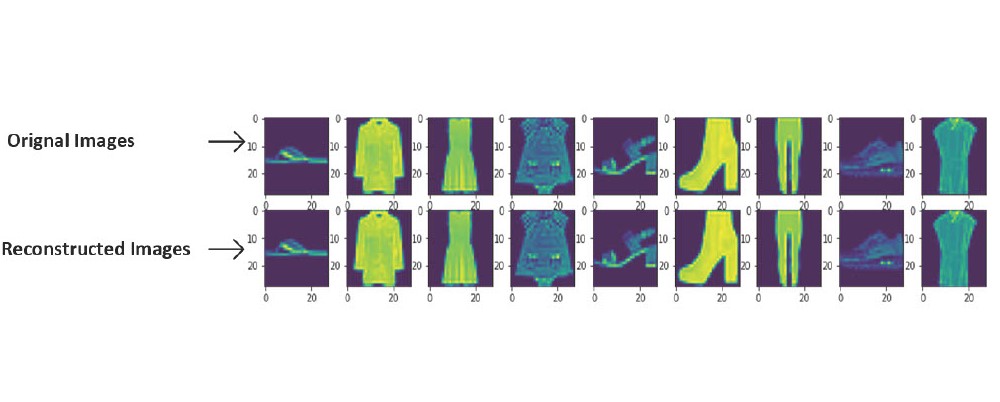
Img Title: Results produced by the GAN
Brief : Generative Adversarial Networks (GANs) similar to VAEs learn to generate new data and consist of two components a generator and a discriminator. The generator
learns to generate new data samples that resemble the training data, while the discriminator learns to distinguish between real and generated data. This adversarial
training process leads to the generation of high-quality and realistic data samples. I've built a GAN model from scratch using TensorFlow and the Keras Sequential API,
with the aim of dataset generation. The image displayed above showcases the achieved results. Throughout the project, the GAN was trained on the
fashion MNIST dataset. My ongoing projects involve further enhancing the
quality of the generated images based on the foundation established by this project.
Code Read Me
Emotion Recognition from Short-Videos
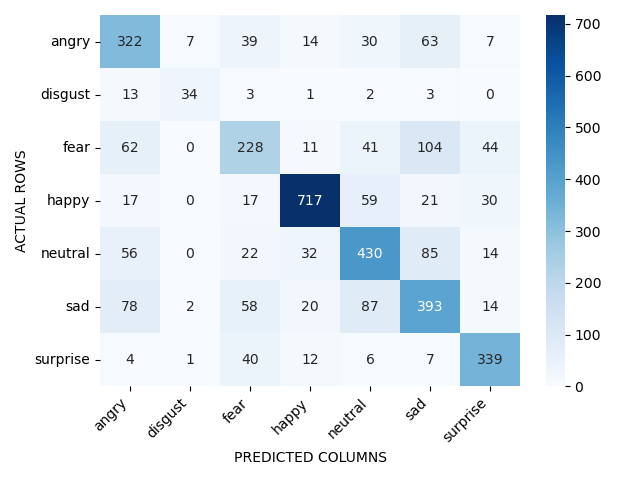
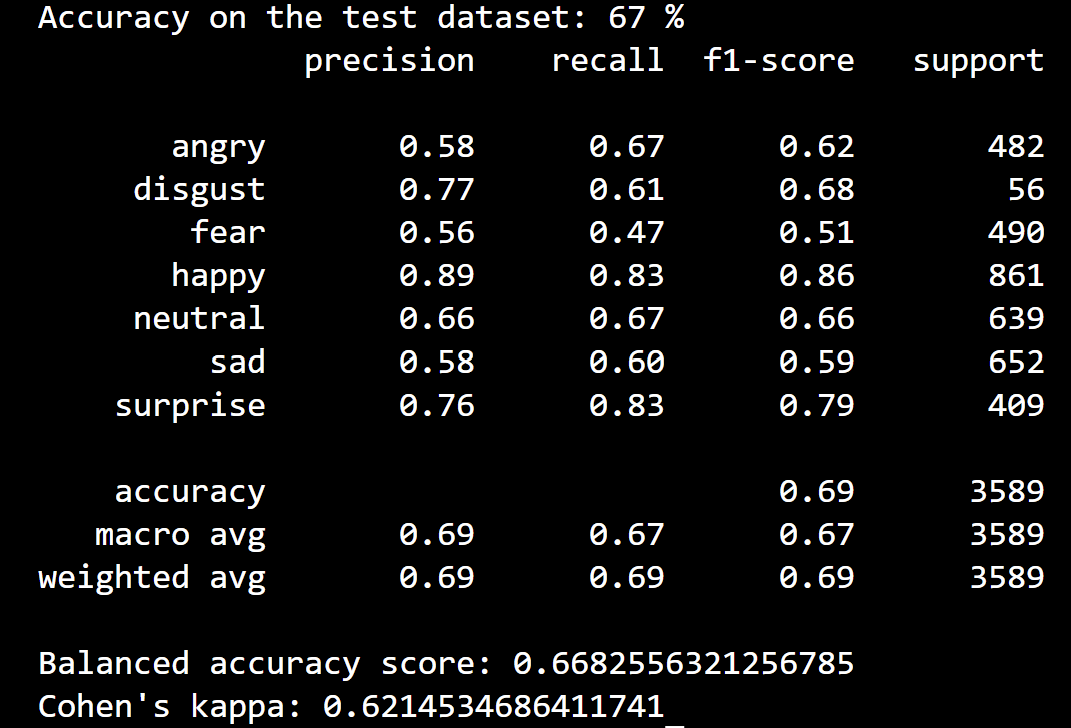
Img Title: Confusion Matrix of Classifier's Performance Across different Emotions
Brief : Advanced machine learning techniques were applied to develop and implement an emotion classification system using PyTorch. Three deep learning models - ResNext50, ResNext101, and VGG19,
were trained on the FER_2013_Kaggle dataset. The models were evaluated on metrics such as Cohen's Kappa and Balanced Accuracy
from Scikit-Learn (see image below). The ResNext101 model yielded the highest accuracy at 67% on test set. An emotion recognition pipeline was created which accepts a short video (up to 5 seconds),
identifies, and ranks the top 3 emotions. This module is part of a larger music recommendation system, utilizing the emotion classification to provide suitable music suggestions.
Code Read Me
Keywords: NLP, SCIBERT, BIOBERT, GPT-2, BigBird.
Document Length Text Classification (On-Going)
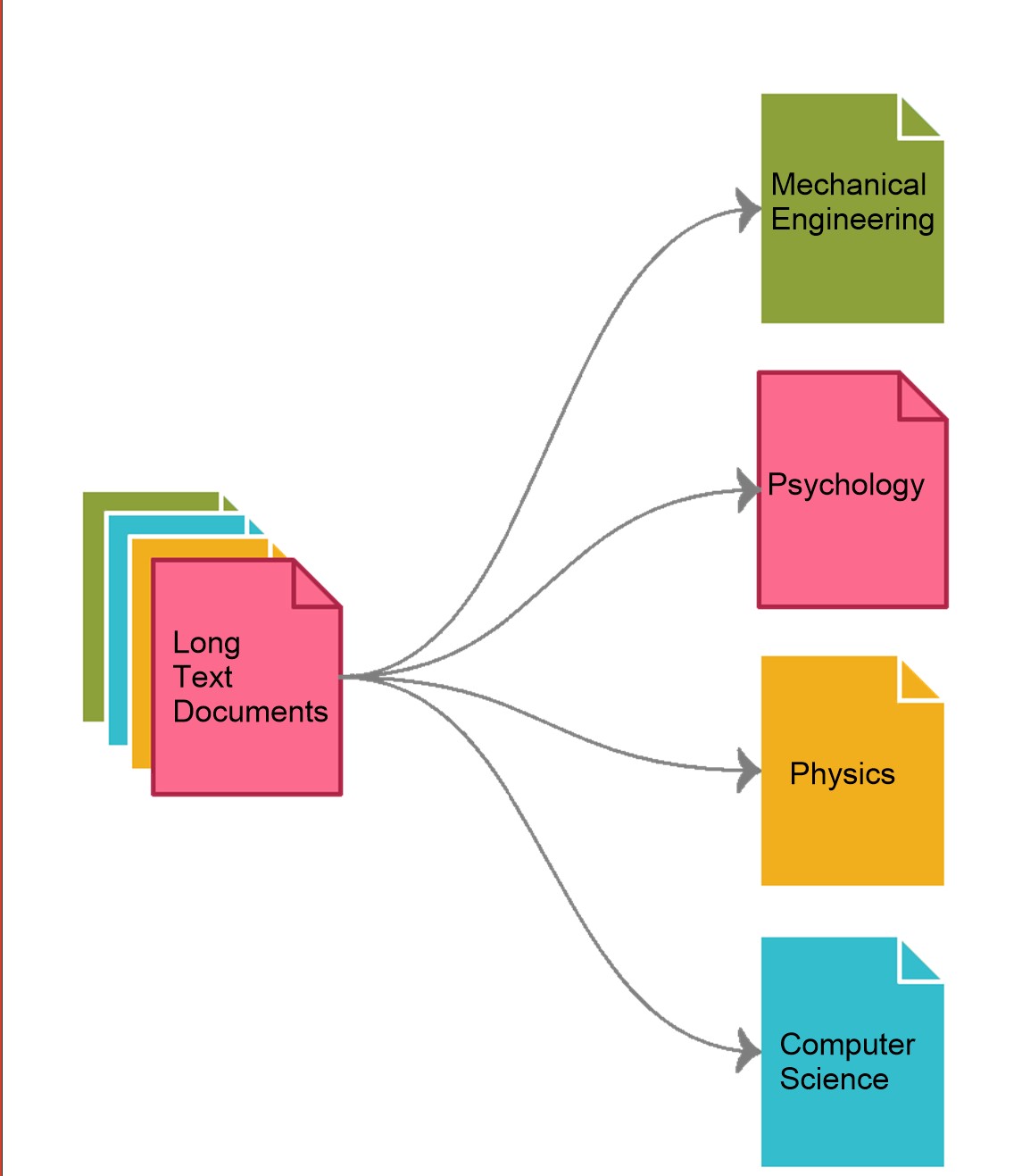
Img Title: Classifying Long Text Documents into 1 of n categories (n=4 here)
Brief : In this key project at Virginia Tech, I've co-developed an advanced text classification pipeline to categorize Electronic Dissertations and Theses (ETDs) into
200 unique STEM and Non-STEM disciplines using state-of-the-art natural language processing models—SciBERT, BioBERT, GPT-2, and BigBird. Fine-tuned on a custom dataset, the models decipher complex patterns within the documents, enhancing the web accessibility and keyword indexability of ETDs.